流行りのAIブームがボイスチェンジャーにもやってきました。
RVCとVC Clientを組み合わせることによって、リアルタイムでAIボイスチェンジャーを利用することができます。
声質は自由自在、学習させたい声の音声ファイルを用意すれば誰だって好きな声で喋ることが可能です。
男性ボイスを女性ボイスに変換した場合のサンプル音声でご確認ください。
普通の地声で喋っています。これの凄さは実際にやってみてお試しください。
2000個のwavファイルを30回学習させた場合(音源はあみたろさんです)
5000個のwavファイルを100回+他の学習モデルを合体させた場合(音源は色々です)
RVC導入方法
こちらを参考にしました。
こちらのリンクからRVCをダウンロードします。
これはVC Clientで音声変換をする際に使用する.pthという拡張子の学習モデルを作るために使用するものです。
![]() からダウンロードして解凍するとgo-web.batが中にあるので、クリックすると以下のようなページが開かれます。
からダウンロードして解凍するとgo-web.batが中にあるので、クリックすると以下のようなページが開かれます。

タブから训练をクリックすると訓練できます。
以下のように設定します。赤枠以外は特に使いません。
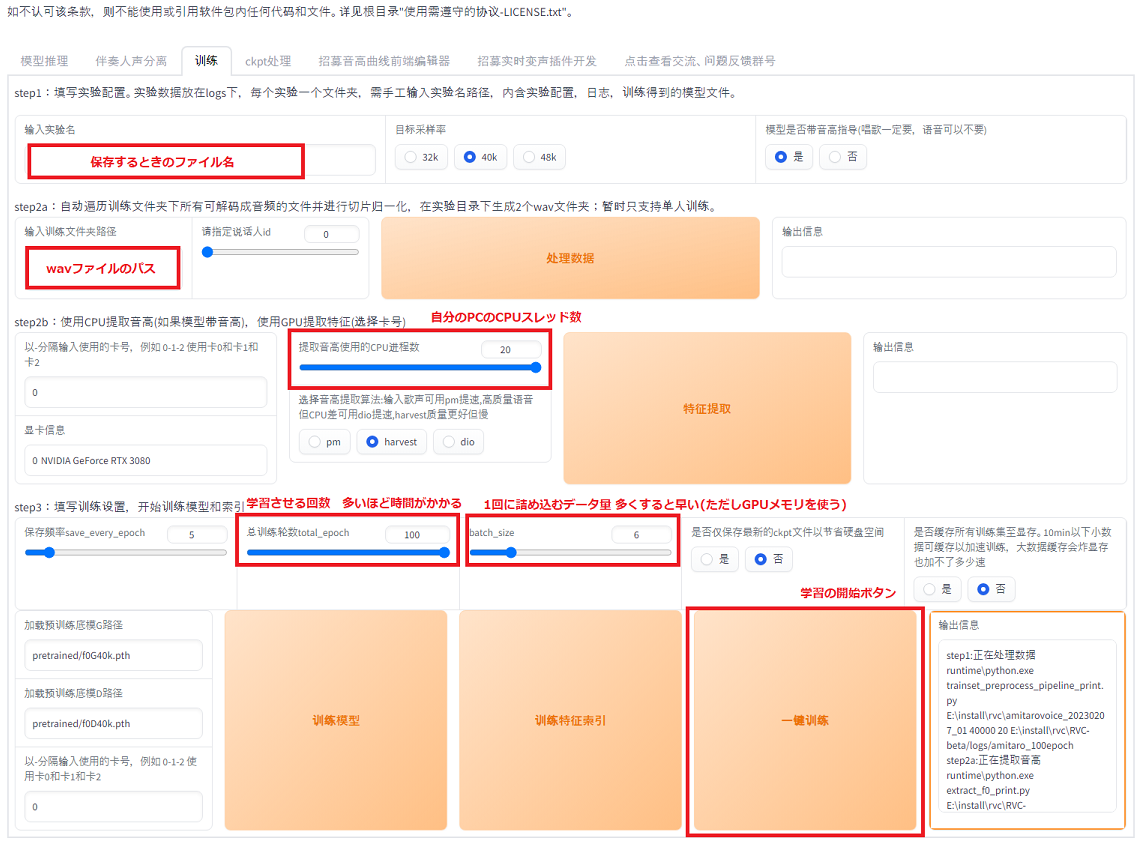
学習を開始したときに一番最初にポップアップが出ますが特に許可しなくても問題ありません。
日本語化した方もいらっしゃいますが、以下で紹介するckpt处理など中国語じゃないと動かない機能もあるようなので日本語化は必要に応じてやるといいと思います。
日本語化する場合は解凍したらgo-web_jp.batとinfer-web_jp.batを元のRVC-betaフォルダの中に追加し、go-web.batではなくgo-web_jp.batを実行します。
ckpt处理ではRVCで作った.pthの拡張子がついたファイル同士の合体ができます。
これにより学習モデル2つの特徴を持った新しい学習モデルが作れます。
合体させる2つのファイルパスと合体後のファイル名を入れてから融合を押すと数秒で似たような別人の学習モデルになります。

学習ファイルの選定
学習モデルに使うwavファイルは最初は以下で試すのが良いと思います。
より多くのwavファイルを突っ込んでみたい方はあみたろさんが公開しているwavファイル全部盛りを一括ダウンロードするのが良いでしょう。およそ2800個のwavファイルがダウンロードできます。
それぞれルールが記載されているので読んでから使ってくださいね。
epoch数は上げるほど機械音声っぽさが無くなりますが時間がかかります。
RTX3080 10GBで上記のあみたろさんのwavファイルを全部突っ込んで100epochでやるとGPUが常時100%に張り付いて6時間ほどかかります。どちらかというとGPUはメモリ数のほうが重要で、Twitter見る限り4GBは厳しいのではとかなんとか。
学習が完了すると\RVC-beta\weightsに53MB程度の学習モデルが保存されます。
このファイルを直接ダウンロードしたり、受け渡しをすれば他の人でもたぶん使えると思いますが利用規約で再頒布はNGな音声データが多いと思います。
あみたろさんのは再頒布が条件付きでOKなようです。詳しくは上記URLからよくある質問を読んで下さい。
あみたろの声素材、およびUTAU音源・小春音アミは、条件付きで再配布OKです。
アプリやMODへの組み込みや、ダウンロード環境のないお友達のかわりにダウンロードしてあげるなど、どうしても再配布する必要がある場合は、遠慮なく再配布してください。
ただし、あみたろの声素材やUTAU音源そのものを販売してお金を稼ぐことはできません。
また、再配布にあたっては必ずあみたろが作成したReadmeを同梱し、事後報告でいいのでご一報ください。
VC Client導入方法
こちらを参考にしました。
こちらのリンクからVC Clientをダウンロードします。
ここではv.1.5.1.15bを使用します。
VC Clientは日本の方が作っているものなので、読めば分かりますが自分の環境にあったやつをダウンロードして解凍します。
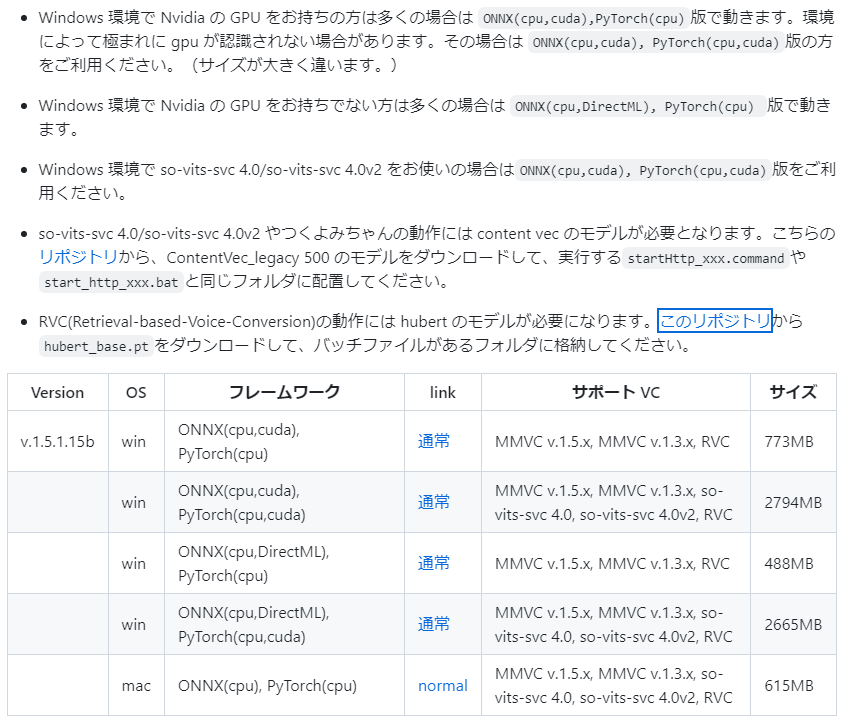
以下リポジトリURLからhubert_base.ptをダウンロードして、「MMVCServerSIO」フォルダ直下に入れます。
(2023/5/8 追記)
バージョンv1.5.2.8ではhubert_base.ptファイルは初回起動時にダウンロードしてくれるようになったので、この作業は不要です。
ただしダウンロードが終わるまで画面真っ白なので次の手順でbatファイルを実行したときにコマンドプロンプトのほうを見ておいてください。
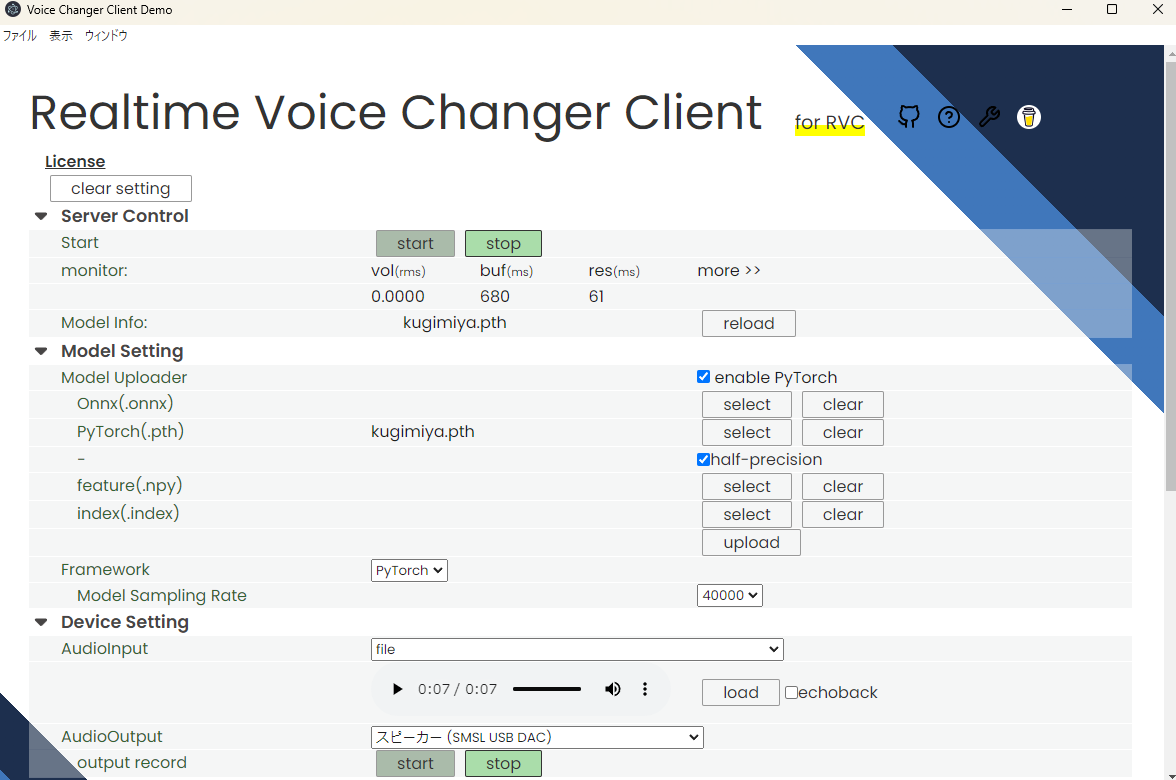
start_http_RVC.batをクリックすると、以下のようなページが開かれます。
pyTorchの欄にRVCで作った.pthの学習モデルを選んでuploadを押します。
(2023/5/8 追記)
バージョンv1.5.2.8ではModel(,onnx or .pth)という欄です。Uploadする前にDefault Tuneという項目も追加されているので、この値を自分の声の高さに合わせて調整してください。男声→女声なら12~15くらいがいいと思います。
Device settingのAudioInputに自分のマイク、AudioOutputにスピーカーとするとリアルタイムでスピーカーに変換された音声が流れることになります。
一番上のServer ControlのStartを押すとリアルタイム変換が開始されます。
開発者さんは動画でも使い方を解説されています。モチベのためにも良かったらコーヒーを奢ってあげましょう。
ノイズが乗ったりresが無限に伸びて困ってる人向け
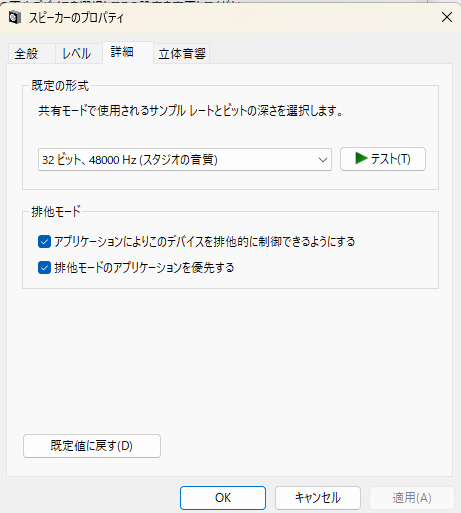
システム>サウンドの詳細設定を開いてスピーカーとマイクのプロパティを開いて
詳細から規定の形式のサンプルレートとビットの深さの値を確認してください。
この値は使用するオーディオデバイスによって異なりますが、48000Hzや44100Hzなど、別の値にしてみて動くか確認するといいと思います。
ついでに参考リンクも貼っときますね
VB-Audio Virtual Cableの導入
Discordで使うために必要な作業です。
VB-Audio Virtual Cableは、Windows上で仮想オーディオデバイスを作成するためのツールです。以下からダウンロードできます。
Discordでリアルタイム音声変換を行うには、以下の手順を実行する必要があります。
- VB-Audio Virtual Cableをインストールし、仮想オーディオデバイスを作成します。
- VC Clientで追加されたAudioOutputを設定します。
- DiscordでVC Clientで設定したのと同じオーディオを選びます。
VC Clientの設定はこんな感じにします。

Discordの設定はこんな感じです。

これで自分には変換後の声は聞こえませんが、相手には変換後の声が伝わります。
ワンテンポ遅れる程度のラグがありますので、速攻で反応しないとだめなシチュエーションには向きません。雑談程度なら気にならないラグです。
wavファイルの素材量産方法
特定の人だけが喋っている音声ファイルだけを選んでノイズを除外して喋っている音声だけ抜き出せば効率的にwavファイルを集めることができます。
RVCに食わせるデータはなるべくその人の声だけがいいのです。音楽や環境音が入っていたり、無音が含まれるデータは学習データとして相応しく有りません。ということでまずはノイズ除去から始めます。
ノイズ除去
ボーカルリムーバーを使用してAIに人が話している音だけを分離してもらいます。
これらのサイトを使うと楽です。
オンライン変換する場合はインターネットアップロードしちゃ駄目なデータは上げないようにしましょう。
オフラインの場合は以下が使えそうです。
SoXの導入
ノイズを除去したことで生まれた無音部分はSoXを使用して削除を行うことで学習データの精度を上げることができます。
SoX (Sound eXchange)とは…オープンソースの音声処理ソフトウェアです。SoXは、音声ファイルを変換、操作、エフェクトをかけたり、音声ファイルから特定の部分を切り出すために使用されます。例えば、SoXを使って音声ファイルから無音部分を自動的に検出し、それを削除することができます。
SoXをダウンロードし、インストールします。
(ここではSox/14.4.2/sox-14.4.2-win32.exeを使用します)
導入方法はこちらに沿って行います。
インストールしただけではmp3が使えないので以下からdllファイルをダウンロードしてdllをsoxと同じフォルダにブチ込みます。
SoXのファイルパスをコピって環境変数の追加を行います。
これでSoXが使えるようになりました。
エクスプローラーで音声ファイルがある場所に移動し、Shiftを押しながら右クリックでコマンドプロンプトまたはターミナルを開き、SoXを使用してmp3を処理します。
例えば、以下のコマンドを使用して、無音部分を切り抜き、人が話している部分のみをwavファイルで抜き出すことができます。
sox -V3 input.mp3 out.wav silence -l 1 0.2 0.1% 1 0.2 0.1%: newfile : restart
このコマンドは、以下のことを行います。(ChatGPTさん解説)
- sox: SoXコマンドを呼び出します。
- -V3: 処理中に詳細な情報を表示します。
- input.mp3: 入力ファイルの名前を指定します。
- out.wav: 出力ファイルの名前を指定します。
- silence: 無音部分を検出するオプションです。
- -l: 無音部分を検出するためのしきい値を設定します。この例では、1が検出する無音の長さ、0.2が無音と判断する音量のしきい値、0.1%が無音部分と認識される最大の音量の割合を示しています。
- 1 0.2 0.1%: 最初の無音部分を検出するパラメータです。
- 1 0.2 0.1%: 2番目の無音部分を検出するパラメータです。
- : newfile: 新しいファイルを開始することを示します。
- : restart: 前のパラメータが検出された後、新しいファイルを作成することを示します。
出力されるwavファイルには連番で001から始まる番号が振られます。
フフフ…SoX…みんなSoXし続けろ…

ちなみにこういうのもあるようです。
以上
圧倒的成長。